次へ
2024年05月09日から06月07まで
★メモリの端子の数が違うのはなぜ、という疑問★
ギャンギャンパソコンの解体のお仕事をしていると代表のHさんに、

「メモリの端子って、なぜコッチ(主記憶装置)はたくさんあって、コッチ(補助記憶装置)は少ないのかなぁ?」
という疑問をいただきました。
日にちが経っているので、すでにHさんはイロイロと調べられていて答えを見つけていらっしゃると思いますが、私なりの稚拙な回答を書いておこうかなと思います。
・間違っていたらごめんねーッ!!
たぶん長くなるので少しずつ書いていきます。
2024年05月09日から06月07まで
★メモリの端子の数が違うのはなぜ、という疑問★
ギャンギャンパソコンの解体のお仕事をしていると代表のHさんに、
「メモリの端子って、なぜコッチ(主記憶装置)はたくさんあって、コッチ(補助記憶装置)は少ないのかなぁ?」
という疑問をいただきました。
日にちが経っているので、すでにHさんはイロイロと調べられていて答えを見つけていらっしゃると思いますが、私なりの稚拙な回答を書いておこうかなと思います。
・間違っていたらごめんねーッ!!
たぶん長くなるので少しずつ書いていきます。
★ザックリな説明★
端的に言うと「データの受け渡し方が違う」ので「配線の仕方も違う」ためです。

CPUと「メインメモリ(主記憶装置)」はほぼ直接つながっていて、そのバス幅(配線のこと。データ線とかデータバスともいう)は64ビットCPUの場合は「64組」です。
・64本じゃなくて64組というのは「入力64本+出力64本=128本」の配線でつないでいるから
・データバスだけではなく他にもイロイロなことが必要なのでDDR4 SDRAMの場合の端子数は288ピン
「NVMe(SSD) 補助記憶装置(メモリ)」はメモリと言っても「メイン」じゃなくてあくまでも「サブ」で周辺機器の1つです。
・要はUSBやディスプレイ、キーボードやマウス、CDやDVD、BD、SDメモリーカードなどと同じ扱い
そういうわけで、
・CPUに直接つながっているのではなく、周辺機器用(古い言葉でI/Oポート、新しい言葉でインターフェースとも言う)のバスにつながっている
・NVMeだとPCI Expressというバスだけれど、このNVMeは切り込みが2つ(M.2のB-M Key)なのでシリアルATA Express→PCI Express×2かなー? もちろん知らンけど…
端的に言うと「データの受け渡し方が違う」ので「配線の仕方も違う」ためです。
CPUと「メインメモリ(主記憶装置)」はほぼ直接つながっていて、そのバス幅(配線のこと。データ線とかデータバスともいう)は64ビットCPUの場合は「64組」です。
・64本じゃなくて64組というのは「入力64本+出力64本=128本」の配線でつないでいるから
・データバスだけではなく他にもイロイロなことが必要なのでDDR4 SDRAMの場合の端子数は288ピン
「NVMe(SSD) 補助記憶装置(メモリ)」はメモリと言っても「メイン」じゃなくてあくまでも「サブ」で周辺機器の1つです。
・要はUSBやディスプレイ、キーボードやマウス、CDやDVD、BD、SDメモリーカードなどと同じ扱い
そういうわけで、
・CPUに直接つながっているのではなく、周辺機器用(古い言葉でI/Oポート、新しい言葉でインターフェースとも言う)のバスにつながっている
・NVMeだとPCI Expressというバスだけれど、このNVMeは切り込みが2つ(M.2のB-M Key)なのでシリアルATA Express→PCI Express×2かなー? もちろん知らンけど…
★低級言語★
さてさて、いよいよメモリについて「低レベル(低級言語)」な話です。
低レベル=頭が悪いとか、そういうわけではなくてコンピュータで「低レベル」というのは、
・コンピュータに近くて人間には遠い→コンピュータにとっては易しくて人間には難しいことを「低レベル」
・逆に「高レベル」はコンピュータには遠くて人間に近い→コンピュータにとっては難しく人間には理解しやすいことを「高レベル」
という意味です。
さてさて、いよいよメモリについて「低レベル(低級言語)」な話です。
低レベル=頭が悪いとか、そういうわけではなくてコンピュータで「低レベル」というのは、
・コンピュータに近くて人間には遠い→コンピュータにとっては易しくて人間には難しいことを「低レベル」
・逆に「高レベル」はコンピュータには遠くて人間に近い→コンピュータにとっては難しく人間には理解しやすいことを「高レベル」
という意味です。
★メモリの中身 スイッチ→ビット(bit)★
コンピュータのメモリ(記憶装置)は人間の記憶とはちょっと違っていて、
・ムチャクチャたくさんスイッチがあって、そのスイッチをつけたり消したり、つまりONかOFF(厳密にいうなら電圧が高い/低い)で記憶したり計算したりする
・コンピュータ(CPU)は基本的に「数しか分からない」
この仕組み(コンピュータ・アーキテクチャ)自体は昔も今(2024年現在)も全然変わっていなくて「何かすごいことが起こらない限りたぶん続くかも…」と思います。
今現在のコンピュータのメモリの仕組みをテーブルタップ(電源タップ)で説明すると…、

・4個口のテーブルタップの例 (本当は8個口が良かったのだが家に無かったので…)
・コンピュータはスイッチがOFFの場合は0、スイッチがONの場合は1と表す
・全部OFFなのだからコンピュータでは「0000」という数字で表される
・人間でいうところの「0」という数字で表される
・コンピュータの「0000」の一つ一つの桁を「ビット(bit)」と呼ぶ
・4桁のビットで数字を表すので「4ビット」と呼ぶ
では、一番右のスイッチをONにすると…、

・一番右の桁(ビット)をONにしたのでコンピュータでは「0001」という数字を表している
・人間でいうところの数字は「1」を表している
コンピュータのメモリ(記憶装置)は人間の記憶とはちょっと違っていて、
・ムチャクチャたくさんスイッチがあって、そのスイッチをつけたり消したり、つまりONかOFF(厳密にいうなら電圧が高い/低い)で記憶したり計算したりする
・コンピュータ(CPU)は基本的に「数しか分からない」
この仕組み(コンピュータ・アーキテクチャ)自体は昔も今(2024年現在)も全然変わっていなくて「何かすごいことが起こらない限りたぶん続くかも…」と思います。
今現在のコンピュータのメモリの仕組みをテーブルタップ(電源タップ)で説明すると…、
・4個口のテーブルタップの例 (本当は8個口が良かったのだが家に無かったので…)
・コンピュータはスイッチがOFFの場合は0、スイッチがONの場合は1と表す
・全部OFFなのだからコンピュータでは「0000」という数字で表される
・人間でいうところの「0」という数字で表される
・コンピュータの「0000」の一つ一つの桁を「ビット(bit)」と呼ぶ
・4桁のビットで数字を表すので「4ビット」と呼ぶ
では、一番右のスイッチをONにすると…、
・一番右の桁(ビット)をONにしたのでコンピュータでは「0001」という数字を表している
・人間でいうところの数字は「1」を表している
★二進法 十進法 十六進法★
ここまでは良いのですが、
・じゃ、人間でいうところの「2」ってコンピュータではどう表すのか?
って思うでしょ? たぶん…。
上記の通り「コンピュータはスイッチのON/OFFで記憶したり計算したりする」「スイッチがOFFの時は0で、ONの時は1」→「記憶装置には0と1の2つしか数字が無い」ので、

・1つのビットにスイッチが1つしかないので「0002」じゃなくて、1つ桁が繰り上がって「0010」が人間でいうところの「2」という表現になる
・人間だと「1+1=2」なのですがコンピュータは「1+1=10」
・0と1の2つの数字でイロイロな数字を表す規則を「二進法」、二進法で表した数を「二進数」という
・俗に二進法を使うことを「デジタル」という
・逆に人間のように「0,1,2,3,4,5,6,7,8,9」の10個(0も1個と数える)の数字で表す規則や表し方を「十進法」と呼ぶ
・余談としては「フランス語とかは二十進法だったりする」ので「人間全員が十進法で数字を使っているわけじゃない」のだが…
写真を撮るのが面倒くさいので文字で書いちゃうと、
・3 (十進法) = 0011 (二進法)
ここまでは良いのですが、
・じゃ、人間でいうところの「2」ってコンピュータではどう表すのか?
って思うでしょ? たぶん…。
上記の通り「コンピュータはスイッチのON/OFFで記憶したり計算したりする」「スイッチがOFFの時は0で、ONの時は1」→「記憶装置には0と1の2つしか数字が無い」ので、
・1つのビットにスイッチが1つしかないので「0002」じゃなくて、1つ桁が繰り上がって「0010」が人間でいうところの「2」という表現になる
・人間だと「1+1=2」なのですがコンピュータは「1+1=10」
・0と1の2つの数字でイロイロな数字を表す規則を「二進法」、二進法で表した数を「二進数」という
・俗に二進法を使うことを「デジタル」という
・逆に人間のように「0,1,2,3,4,5,6,7,8,9」の10個(0も1個と数える)の数字で表す規則や表し方を「十進法」と呼ぶ
・余談としては「フランス語とかは二十進法だったりする」ので「人間全員が十進法で数字を使っているわけじゃない」のだが…
写真を撮るのが面倒くさいので文字で書いちゃうと、
・3 (十進法) = 0011 (二進法)
・4 (十進法) = 0100 (二進法)
・5 (十進法) = 0101 (二進法)
…と続いて行って4ビットの桁を全部1(スイッチをON)にすると、

・コンピュータでいうところの二進法は「1111」
・人間でいうところの十進法は「15」
・つまり4ビット(4桁)で扱える数字は「2^4(2の4乗)」で「0から15まで」もしくは「-8から+7」の16通りとなる (0も1個として数える、マイナスの値は話がややこしくなるので今後割愛)
ちなみに二進法では「とにかく桁が多くなっちゃう」のでプログラム(今でいうところのアプリ)を作ったりする時は可読性(読みやすさ)を良くするために、
・0,1,2,3,4,5,6,7,8,9,A,B,C,D,E,Fの「十六進法(16個の数字で表す)」を使うことが多い
・二進法(二進数)の「1111」は十進法(十進数)で「15」、十六進法(十六進数)では「F」
・要は4ビットの二進数の全部スイッチがONの「1111」が十六進数では最後の数字の「F」になるので分かりやすい
これはプログラムを組みたい(アプリを作りたい)人向けの説明なので、
・二進法(二進数)の「1010」=十進法(十進数)では「10」=十六進法(十六進数)では「A」ってイチイチ計算したり覚えたりする必要はない
です。
…と続いて行って4ビットの桁を全部1(スイッチをON)にすると、
・コンピュータでいうところの二進法は「1111」
・人間でいうところの十進法は「15」
・つまり4ビット(4桁)で扱える数字は「2^4(2の4乗)」で「0から15まで」もしくは「-8から+7」の16通りとなる (0も1個として数える、マイナスの値は話がややこしくなるので今後割愛)
ちなみに二進法では「とにかく桁が多くなっちゃう」のでプログラム(今でいうところのアプリ)を作ったりする時は可読性(読みやすさ)を良くするために、
・0,1,2,3,4,5,6,7,8,9,A,B,C,D,E,Fの「十六進法(16個の数字で表す)」を使うことが多い
・二進法(二進数)の「1111」は十進法(十進数)で「15」、十六進法(十六進数)では「F」
・要は4ビットの二進数の全部スイッチがONの「1111」が十六進数では最後の数字の「F」になるので分かりやすい
これはプログラムを組みたい(アプリを作りたい)人向けの説明なので、
・二進法(二進数)の「1010」=十進法(十進数)では「10」=十六進法(十六進数)では「A」ってイチイチ計算したり覚えたりする必要はない
です。
★パラレル通信(転送) シリアル通信(転送)★
これを踏まえての「主記憶装置(メインメモリ)は端子がいっぱいあるのに、補助記憶装置(サブメモリ)はちょっとしかないのか」というと、

・主記憶装置(メインメモリ)は1ビット(それぞれの桁)に1本ずつ入力と出力のデータの線をCPUへつなぐと、CPUに1回で全部の桁の数字(データ)を送る/戻すだけで済むから「速いンじゃね?」
・こういう接続を「パラレル通信」「パラレル転送」という
図は4ビット(4組、8本)なので「そんなに速いンか?」と思う方もいらっしゃるかもしれませんが、
・8ビットだったら8組(16本)の数字の組み合わせ(扱える数字の数)は2^8=十進数で256通り
・16ビットなら2^16=十進数で65536通り
・32ビットなら2^32=十進数で4294967296通り
・今、現在主流の64ビットなら2^64=十進数で18446744073709551616通り
と、
・扱える数字の桁が多すぎるから1度にドバっと送った方がイイかもしれない…
これを踏まえての「主記憶装置(メインメモリ)は端子がいっぱいあるのに、補助記憶装置(サブメモリ)はちょっとしかないのか」というと、
・主記憶装置(メインメモリ)は1ビット(それぞれの桁)に1本ずつ入力と出力のデータの線をCPUへつなぐと、CPUに1回で全部の桁の数字(データ)を送る/戻すだけで済むから「速いンじゃね?」
・こういう接続を「パラレル通信」「パラレル転送」という
図は4ビット(4組、8本)なので「そんなに速いンか?」と思う方もいらっしゃるかもしれませんが、
・8ビットだったら8組(16本)の数字の組み合わせ(扱える数字の数)は2^8=十進数で256通り
・16ビットなら2^16=十進数で65536通り
・32ビットなら2^32=十進数で4294967296通り
・今、現在主流の64ビットなら2^64=十進数で18446744073709551616通り
と、
・扱える数字の桁が多すぎるから1度にドバっと送った方がイイかもしれない…
逆に補助記憶装置(サブメモリ)のデータのやり取りは、

・何本かのデータの線(基本は1組だが)を使って「1桁ごと(1ビットごと)」に順番に数字を送受信する感じ
・こういうのを「シリアル通信」「シリアル転送」という
・今トレンドな通信方法だったりする

・シリアル通信の場合はパラレル通信とは違ってデータの線が少なくて済む
・シリアル通信の代表格であるUSB(ユニバーサル「シリアル」バス) A端子(コネクタ)の場合、2番と3番がデータで1番と4番は電源と「わずか4本」とシンプルで5mくらい線を作っても大丈夫
図でのシリアル通信の際に、
・「0」→「0」→「1」→「0」と大きい桁からビットを転送することを「ビッグエンディアン」
・「0」→「1」→「0」→「0」と小さい桁からビットを転送することを「リトルエンディアン」
というのですが、
・エンディアンを考えなくちゃいけないのはプログラムを組むときに限られるから「気にしなくてもいい」
と思います。
今までコンピュータの数のビットを「ビッグエンディアン」で書いてきました。
日常生活の中であえて意識するなら「日付の読み方」で例えば2024年05月14日の場合、
・日本や中国などは2024-05-14と「年月日」という順番なのでビッグエンディアン
・ヨーロッパは14-05-2024と「日月年」という順番なのでリトルエンディアン
・アメリカは05-14-2024と「月日年」という順番なのでミドルエンディアン
という感じで。
★ビット(bit)とバイト(Byte)★
話を元に戻して、今、現在のコンピュータの感覚としては4ビットではなく、

・メモリの最小単位は8ビットが基本となっている
・8ビット(bit)をひとまとめにして1バイト(Byte)と呼んでいる
・慣例としてビットは「bit」と小文字で、バイトは「Byte」と大文字を使う
どうして8ビット(bit)=1バイト(Byte)が基本なのかというと上記ですでにお話ししたように、
・8ビットは2^8=256通りの数字が扱えるから
なぜ、2ビットや4ビットではないのかというと、
・電卓だったら2ビットや4ビットでも余裕だがパソコンみたいな「いろいろな目的に使うコンピュータ」だと扱える数字が少なすぎてチョイと厳しい…
話を元に戻して、今、現在のコンピュータの感覚としては4ビットではなく、
・メモリの最小単位は8ビットが基本となっている
・8ビット(bit)をひとまとめにして1バイト(Byte)と呼んでいる
・慣例としてビットは「bit」と小文字で、バイトは「Byte」と大文字を使う
どうして8ビット(bit)=1バイト(Byte)が基本なのかというと上記ですでにお話ししたように、
・8ビットは2^8=256通りの数字が扱えるから
なぜ、2ビットや4ビットではないのかというと、
・電卓だったら2ビットや4ビットでも余裕だがパソコンみたいな「いろいろな目的に使うコンピュータ」だと扱える数字が少なすぎてチョイと厳しい…
★参考資料の紹介★
だいぶん自分で絵を描くのがしんどくなってきたので資料を使って引用しながらお伝えします。引用する本は、

・SONYのMSX2+ 「MSX-BASIC Version 3.0 文法書」 説明書のオマケなので非売品
・湯浅 敬著の「MSX マシン語入門講座」 ISBN4-87148-761-X C3055 P1650E 1650円 古い本なのでたぶん絶版
・MSXはとても古いパソコンなのですが基本的なことは今も昔も全然変わっていないのでOKかなー、と思いまして…
だいぶん自分で絵を描くのがしんどくなってきたので資料を使って引用しながらお伝えします。引用する本は、
・SONYのMSX2+ 「MSX-BASIC Version 3.0 文法書」 説明書のオマケなので非売品
・湯浅 敬著の「MSX マシン語入門講座」 ISBN4-87148-761-X C3055 P1650E 1650円 古い本なのでたぶん絶版
・MSXはとても古いパソコンなのですが基本的なことは今も昔も全然変わっていないのでOKかなー、と思いまして…
★1バイト文字 文字コード★
なぜ1Byte(1バイト=8ビット,8bit)くらい欲しいのかというと、
・コンピュータって昔からアメリカ中心でアメリカって英語だよねー
・英語は英語のアルファベットで文字を表していて大文字と小文字がそれぞれ「A,B,C,D,E,F,G,H,I,J,K,L,M,N,O,P,Q,R,S,T,U,V,W,X,Y,Z」「a,b,c,d,e,f,g,h,i,j,k,l,m,n,o,p,q,r,s,t,u,v,w,x,y,z」の合計52文字は最低いる
・英語の場合は「 (スペース)」で単語を区切るので「 (スペース)」として1文字欲しいし、文章の終わりの「.(ピリオド,終止符)」や文章を区切る「,(コンマ)」も1文字ずつ欲しいし、アラビア数字の「0,1,2,3,4,5,6,7,8,9」の10文字とかも欲しいし、ちょっとした記号も欲しいよねー
そーゆー事をなんやかんや言ってたら、
・英語とかフランス語とかは100文字から130文字くらいあれば何とかなるので、せいぜい1Byte(バイト)=8bit(ビット)=256通り(256文字)あれば十分かなー
・1バイトで表す文字のことを「1バイト文字」「1バイト言語」という
ということになっちゃったというか「今も昔も欧米の人の都合でコンピュータの規格が決まっちゃう」ので、例えば古のパソコンMSXの文字コード(1バイト文字の場合)は下図の通りになります。

・MSX-BASICで扱える文字コードの表(1バイト文字の場合,上記のSONYの文法書のP258からの引用)
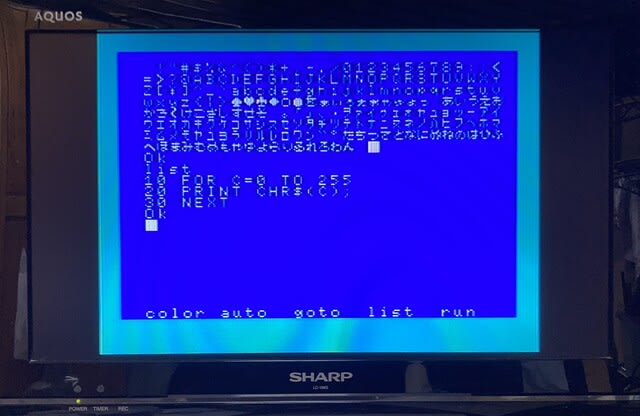
・プログラムを組んで1バイト文字を表示した例
文字コードというのは「文字を数字で表す」ことです。
一番最初に「コンピュータ(CPU)は数字しか分からない」と書きましたが、本当に数字しか分からないので、文字に対して数字を表示してしまったらこれはこれで人間が困るため、


・例えば、パソコンで文章を打った時(キーボードをたたいた時)に「キーボードのボタン"a"が押されたのを感知(キーボードも数字で管理されている)」→「数字で割り当てられた文字の図形(コンピュータグラフィックス、CGとも言う)を表示」→「あたかも文字を打っているように見せてる」
と、いうわけです。
MSX-BASICの文字コードを言い換えると、
・コンピュータにとっては「A」は「0100 0001(二進数)=65(十進数)=41(十六進数)」で、「a」は「0110 0001(二進数)=97(十進数)=61(十六進数)」って事になる
MSXは日本で規格されたパソコンなので、
・1バイト文字の中に「ひらがなやカタカナを無理やりナントカ収めている(各55文字くらい)」
・ただ、日本語はひらがなやカタカナの他に漢字(常用漢字だけで2000字くらい)を使うので「255文字では全然足りてない…」
・1バイト文字だけだと「英数字とひらがな、カタカナだけでほぼ埋まってしまって漢字を入れる個数が足りない」ので日本語としてかなり読みにくい
・日本語を母国語にしている日本人とかは「ひらがな」「カタカナ」「漢字」「英語アルファベット(ローマ字とか)」をセットで習うため、最悪ひらがなだけでも意味は通じてしまう
そういうこともあって、

・図はMSX2版「ドラゴンクエスト(ドラクエI)」
・MSXやファミコン(ファミリーコンピュータ)などの昔のゲーム(レトロゲーム)で「英数字とひらがな、カタカナくらいしかない」のは1バイト文字でナントカ収めようとしていたから
・図の台詞を日本語を母国語にしている人なら漢字交じりにしなくても「勇者"あいてあ"よ! 竜王を倒し その手から光の玉を取り戻してくれ!」と意味があながち分かってしまうので「ひらがなだけでも支障が起きにくい」
・漢字が表示されるゲームも存在したが、この場合「そのゲームで全く使わない1バイト文字のグラフィックを漢字に描き直して表示」とか「文字を表示するときだけ"文字を新しく描き直し"ながら表示」みたいな「涙ぐましい努力」があったりする
なぜ1Byte(1バイト=8ビット,8bit)くらい欲しいのかというと、
・コンピュータって昔からアメリカ中心でアメリカって英語だよねー
・英語は英語のアルファベットで文字を表していて大文字と小文字がそれぞれ「A,B,C,D,E,F,G,H,I,J,K,L,M,N,O,P,Q,R,S,T,U,V,W,X,Y,Z」「a,b,c,d,e,f,g,h,i,j,k,l,m,n,o,p,q,r,s,t,u,v,w,x,y,z」の合計52文字は最低いる
・英語の場合は「 (スペース)」で単語を区切るので「 (スペース)」として1文字欲しいし、文章の終わりの「.(ピリオド,終止符)」や文章を区切る「,(コンマ)」も1文字ずつ欲しいし、アラビア数字の「0,1,2,3,4,5,6,7,8,9」の10文字とかも欲しいし、ちょっとした記号も欲しいよねー
そーゆー事をなんやかんや言ってたら、
・英語とかフランス語とかは100文字から130文字くらいあれば何とかなるので、せいぜい1Byte(バイト)=8bit(ビット)=256通り(256文字)あれば十分かなー
・1バイトで表す文字のことを「1バイト文字」「1バイト言語」という
ということになっちゃったというか「今も昔も欧米の人の都合でコンピュータの規格が決まっちゃう」ので、例えば古のパソコンMSXの文字コード(1バイト文字の場合)は下図の通りになります。
・MSX-BASICで扱える文字コードの表(1バイト文字の場合,上記のSONYの文法書のP258からの引用)
・プログラムを組んで1バイト文字を表示した例
文字コードというのは「文字を数字で表す」ことです。
一番最初に「コンピュータ(CPU)は数字しか分からない」と書きましたが、本当に数字しか分からないので、文字に対して数字を表示してしまったらこれはこれで人間が困るため、
・例えば、パソコンで文章を打った時(キーボードをたたいた時)に「キーボードのボタン"a"が押されたのを感知(キーボードも数字で管理されている)」→「数字で割り当てられた文字の図形(コンピュータグラフィックス、CGとも言う)を表示」→「あたかも文字を打っているように見せてる」
と、いうわけです。
MSX-BASICの文字コードを言い換えると、
・コンピュータにとっては「A」は「0100 0001(二進数)=65(十進数)=41(十六進数)」で、「a」は「0110 0001(二進数)=97(十進数)=61(十六進数)」って事になる
MSXは日本で規格されたパソコンなので、
・1バイト文字の中に「ひらがなやカタカナを無理やりナントカ収めている(各55文字くらい)」
・ただ、日本語はひらがなやカタカナの他に漢字(常用漢字だけで2000字くらい)を使うので「255文字では全然足りてない…」
・1バイト文字だけだと「英数字とひらがな、カタカナだけでほぼ埋まってしまって漢字を入れる個数が足りない」ので日本語としてかなり読みにくい
・日本語を母国語にしている日本人とかは「ひらがな」「カタカナ」「漢字」「英語アルファベット(ローマ字とか)」をセットで習うため、最悪ひらがなだけでも意味は通じてしまう
そういうこともあって、
・図はMSX2版「ドラゴンクエスト(ドラクエI)」
・MSXやファミコン(ファミリーコンピュータ)などの昔のゲーム(レトロゲーム)で「英数字とひらがな、カタカナくらいしかない」のは1バイト文字でナントカ収めようとしていたから
・図の台詞を日本語を母国語にしている人なら漢字交じりにしなくても「勇者"あいてあ"よ! 竜王を倒し その手から光の玉を取り戻してくれ!」と意味があながち分かってしまうので「ひらがなだけでも支障が起きにくい」
・漢字が表示されるゲームも存在したが、この場合「そのゲームで全く使わない1バイト文字のグラフィックを漢字に描き直して表示」とか「文字を表示するときだけ"文字を新しく描き直し"ながら表示」みたいな「涙ぐましい努力」があったりする
★2バイト文字 全角と半角の違い★
もちろん中国語(簡体字、繁体字)や朝鮮語(ハングル)は何千、何万字とあるので、256種類しかない1バイト文字では全く足りないし、日本語も漢字を使うとすれば2000字くらいは普通に欲しいので…、
・1バイト(8ビット)文字+1バイト文字=2バイト(1バイト文字を2つくっつけて)で1文字を表現しよう→こういうのを「2バイト文字」「2バイト言語」という
・2Byte(バイト)=256bit(ビット)×256bit=2^8(2の8乗)×2^8=2^16(2の16乗)bit(ビット)=16bit(16ビット)=65536通り (十進数)
・要は2バイトで文字を表現すると「65536通り」だから「65536種類の文字が表現できる」ため「英数字はもちろん、ひらがなやカタカナ、漢字とかを入れても当面の間は大丈夫じゃね?」
そういうわけで日本向けのパソコンでは日本語を使うために、


・2バイト文字の「JISコード」と「JIS漢字コード」というのが規格された
・今でいうところの「Shift_JIS」の元になったものかなぁ…と
・この規格自体は結構前からあったのだが漢字ROM(今でいうところの漢字のフォント、CG)がMSXに正式に搭載されたのはMSX2+からと、かなり遅かったのでMSXのゲームで漢字ROMが使われることはあまり無かった(たぶん数本くらいしかない)
・そもそも漢字ROM自体が当時15000円-30000円くらいの「かなり高い値段」のため、基本的にはオプション扱いで、当時のパソコンだと20万円くらいの「PC-8801mkII」とかでない限り標準搭載とはいかなかった
・まー、MSXとかファミコンみたいな「本体価格が数万円で中学生のこづかいで買える設定」だと「漢字を表示させるためだけの漢字ROMを搭載することは厳しいよねー」
それはそうと図が小さくて申し訳ないのですが注目してもらいたいのが、

・2バイト文字で漢字の「漢」という字はコンピュータ的(→MSXの2バイト文字としては)には&H3341(&Hは十六進数の略)、十進数に直すと13121
・「A」は&H2341で十進数だと9025、「a」は&H2361で十進数だと9057
何が言いたいのかと言うとコンピュータとしては、
・「A」は1バイト文字なので&H41
・「A」は2バイト文字なので&H2341
・「a」は1バイト文字なので&H61
もちろん中国語(簡体字、繁体字)や朝鮮語(ハングル)は何千、何万字とあるので、256種類しかない1バイト文字では全く足りないし、日本語も漢字を使うとすれば2000字くらいは普通に欲しいので…、
・1バイト(8ビット)文字+1バイト文字=2バイト(1バイト文字を2つくっつけて)で1文字を表現しよう→こういうのを「2バイト文字」「2バイト言語」という
・2Byte(バイト)=256bit(ビット)×256bit=2^8(2の8乗)×2^8=2^16(2の16乗)bit(ビット)=16bit(16ビット)=65536通り (十進数)
・要は2バイトで文字を表現すると「65536通り」だから「65536種類の文字が表現できる」ため「英数字はもちろん、ひらがなやカタカナ、漢字とかを入れても当面の間は大丈夫じゃね?」
そういうわけで日本向けのパソコンでは日本語を使うために、
・2バイト文字の「JISコード」と「JIS漢字コード」というのが規格された
・今でいうところの「Shift_JIS」の元になったものかなぁ…と
・この規格自体は結構前からあったのだが漢字ROM(今でいうところの漢字のフォント、CG)がMSXに正式に搭載されたのはMSX2+からと、かなり遅かったのでMSXのゲームで漢字ROMが使われることはあまり無かった(たぶん数本くらいしかない)
・そもそも漢字ROM自体が当時15000円-30000円くらいの「かなり高い値段」のため、基本的にはオプション扱いで、当時のパソコンだと20万円くらいの「PC-8801mkII」とかでない限り標準搭載とはいかなかった
・まー、MSXとかファミコンみたいな「本体価格が数万円で中学生のこづかいで買える設定」だと「漢字を表示させるためだけの漢字ROMを搭載することは厳しいよねー」
それはそうと図が小さくて申し訳ないのですが注目してもらいたいのが、
・2バイト文字で漢字の「漢」という字はコンピュータ的(→MSXの2バイト文字としては)には&H3341(&Hは十六進数の略)、十進数に直すと13121
・「A」は&H2341で十進数だと9025、「a」は&H2361で十進数だと9057
何が言いたいのかと言うとコンピュータとしては、
・「A」は1バイト文字なので&H41
・「A」は2バイト文字なので&H2341
・「a」は1バイト文字なので&H61
・「a」は2バイト文字なので&H2361
と人間にとっては同じAでもコンピュータにとっては「全く違う文字」ということになります。さらに付け加えるなら、
・「A」(&H2341)と「A」(&H41)はそれぞれ全角と半角
・多くのWebサイトやWebブラウザは「全角のAは日本語として」「半角のAは英語として」処理や判断をする
・2バイト文字の「A」の&H2341や「漢」の&H3341という数字は「あくまで日本語を使うためのJISコードやJIS漢字コード等で割り振った番号」なので「日本語以外のパソコンでは使えなかったり違う文字になってしまう(いわゆる文字化け)」
少し脱線してしまうのですが「文字化け」を起こさない工夫として例えばこのページの場合だと、

・1行目に<!DOCTYPE html>→このファイルはHTML文書ファイルです
・2行目に<html lang="ja">→日本語です
・3行目に<head>→ここから文書のヘッダーです(タイトルなどを入れていきます)
・4行目に<meta charset="UTF-8">→UTF-8(Unicode)の文字コードを使って書きます
この4行がこの順番で書いていないとWebブラウザが「何のファイルかなぁ」とか「文書だと何語で文字コード(日本語だけでも複数ある)は何なのかなぁ」って事になって、
・分かんなかったら、とりあえず「英語にしておこう」とか「日本語っぽいけれど分からないからShift_JISでイイや…」→文字化けが起こる
みたいな感じです。もちろん、
・機種依存文字が最大の文字化け原因なのだが…
とりわけ、

・ミンナがパソコンを持てるようになったのは1980年代からで、かれこれ40年くらい経つけれど、メールアドレスやログインパスワードなどは「未だに1バイト文字の半角英数字(もう少し厳密に言うならASCII)以外は受けつけ無い」とか、どーよッ!!
・今のパソコンだとUnicode(全言語の文字の統一した番号のセット)がホントは使えるのだが「Unicodeに入れる文字をめぐって各国が争ってて決着もしていないので、Unicodeの種類だけが増えてしまった」なのはニントモカントモ…
・Unicodeが普及するにつれて「格段に文字化けが減った」ので「残念とまでは言えないが…」
と人間にとっては同じAでもコンピュータにとっては「全く違う文字」ということになります。さらに付け加えるなら、
・「A」(&H2341)と「A」(&H41)はそれぞれ全角と半角
・多くのWebサイトやWebブラウザは「全角のAは日本語として」「半角のAは英語として」処理や判断をする
・2バイト文字の「A」の&H2341や「漢」の&H3341という数字は「あくまで日本語を使うためのJISコードやJIS漢字コード等で割り振った番号」なので「日本語以外のパソコンでは使えなかったり違う文字になってしまう(いわゆる文字化け)」
少し脱線してしまうのですが「文字化け」を起こさない工夫として例えばこのページの場合だと、
・1行目に<!DOCTYPE html>→このファイルはHTML文書ファイルです
・2行目に<html lang="ja">→日本語です
・3行目に<head>→ここから文書のヘッダーです(タイトルなどを入れていきます)
・4行目に<meta charset="UTF-8">→UTF-8(Unicode)の文字コードを使って書きます
この4行がこの順番で書いていないとWebブラウザが「何のファイルかなぁ」とか「文書だと何語で文字コード(日本語だけでも複数ある)は何なのかなぁ」って事になって、
・分かんなかったら、とりあえず「英語にしておこう」とか「日本語っぽいけれど分からないからShift_JISでイイや…」→文字化けが起こる
みたいな感じです。もちろん、
・機種依存文字が最大の文字化け原因なのだが…
とりわけ、
・ミンナがパソコンを持てるようになったのは1980年代からで、かれこれ40年くらい経つけれど、メールアドレスやログインパスワードなどは「未だに1バイト文字の半角英数字(もう少し厳密に言うならASCII)以外は受けつけ無い」とか、どーよッ!!
・今のパソコンだとUnicode(全言語の文字の統一した番号のセット)がホントは使えるのだが「Unicodeに入れる文字をめぐって各国が争ってて決着もしていないので、Unicodeの種類だけが増えてしまった」なのはニントモカントモ…
・Unicodeが普及するにつれて「格段に文字化けが減った」ので「残念とまでは言えないが…」
★メモリーアドレス 1bit 1Byte★
話が脱線気味だったので元に戻して「メモリの仕組み」を再び書いていきます。
さっきまでの話で何となくお分かりいただけたと思うのですがポイントとしては、
・コンピュータのメモリ(記憶)はスイッチのON/OFF(bit)で記憶する
・1bit(ビット)が最小単位
・1Byte(バイト)は8bitを1つにまとめたもので今のコンピュータでは基本の単位
・1バイト文字は1Byte(8bit)で表現できる文字で2^8(2の8乗)=256通り
・2バイト文字は2Byte(8bit+8bit)で表現できる文字で2^16(2の16乗)で65536通り
では、実際どういう風に記憶しているのかというとMSXの場合は、

・8bit(ビット)を1Byte(バイト)という箱(黄色い枠)に「メモリーアドレス」という番号をつけて管理している(まー、MSXに限らず今のパソコンも同じなのだが)
・1Byte(バイト)の箱=8bit(ビット)なので、今までお話しした通り0から255までの値を記憶することができる
・MSXの場合、メモリーアドレス(メモリの箱、つまり1Byteのそれぞれの番号)は、0番から65535番まで(十進数表記)=&H0000から&HFFFFまで(十六進数表記)を主記憶装置として記憶することができる
・ちなみに1Byte(バイト)=8bit(ビット)だから、主記憶装置のメモリのスイッチ=1bitの数は65536*8(65536×8)=524288個
「えー、また番号とか数字ばっかりで勘弁してよねーッ!!」
と言われても最初に書いた通り、
・CPUが数字しか分からないので「仕方ないよねーッ!!」

・iTunesのアラニス・モリセットのアルバム「Jagged Little Pill」
・私の好きな曲「You Oughta Know」はトラック2
・You Oughta Knowを聞きたいときは2番を押せば「You Oughta Knowの曲データが読み込まれて聴く(再生する)ことができる」
・ザックリとした説明をすると「音楽CD(CD-DA)の場合はトラック番号がちょうどメモリでいうところのメモリーアドレス」かなー、と(実際はもう少し細かいのだが)
・トラック番号が無いと好きな曲をポンと聴きたくても最初からずっと聴かないといけないので「ちょっと不便」だよねー
・メモリーアドレスは&H0000(0番)から&HFFFF(65535番)までとか番号が多いので一見難しそうだが「CDのトラック番号と意味合いは同じ」
ちなみにアドレスバスというのは配線のことで、
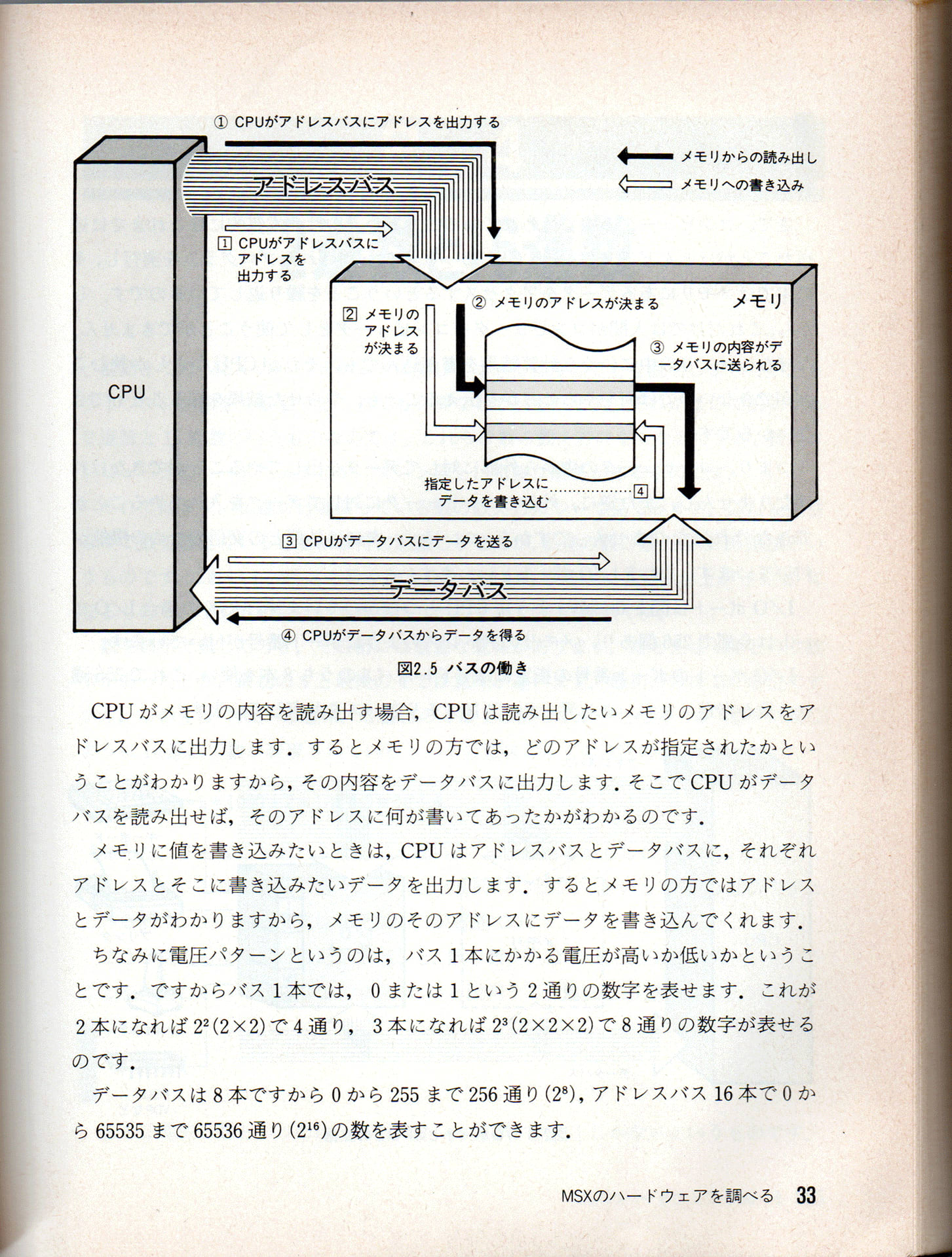
・MSX マシン語入門講座 P33からの引用
・実際にCPUからメモリへ16bit(16本)の配線があるから
もしアドレスバスが8bit(8本)しかなかったら、
・2^8(2の8乗)=256通り、つまりメモリの箱が256個(=256Byte)しかない、もしくはCPUが256Byteまでしか分からないって事になるので「メモリが少なすぎるよねー」
例えば「文字を表示したい」時は多くの場合、
・メモリに記憶されているものを使って文字を表示する
・っつーか、文字以外でも画面表示とかディスクを動かすとか「CPUのお仕事は計算もするけどメモリに記憶してあるものを使ったり記憶を書き換えたりすることも多い」「主記憶装置(メモリ)とはかなり頻繁にやり取りする」
ので、
・「メモリアドレス」や「メモリそのものの」が256Byte(バイト)しかなかったら「1バイト文字だと1バイトのメモリの箱を使う(=1Byte)ので最大256文字、2バイト文字だと1バイトのメモリの箱を2つ使う(=2Byte)ので最大128文字」でいっぱいになる計算だから「文章としては少なすぎるよねー」「俳句だったら31文字だから入るだろうけれど…」
話が脱線気味だったので元に戻して「メモリの仕組み」を再び書いていきます。
さっきまでの話で何となくお分かりいただけたと思うのですがポイントとしては、
・コンピュータのメモリ(記憶)はスイッチのON/OFF(bit)で記憶する
・1bit(ビット)が最小単位
・1Byte(バイト)は8bitを1つにまとめたもので今のコンピュータでは基本の単位
・1バイト文字は1Byte(8bit)で表現できる文字で2^8(2の8乗)=256通り
・2バイト文字は2Byte(8bit+8bit)で表現できる文字で2^16(2の16乗)で65536通り
では、実際どういう風に記憶しているのかというとMSXの場合は、
・8bit(ビット)を1Byte(バイト)という箱(黄色い枠)に「メモリーアドレス」という番号をつけて管理している(まー、MSXに限らず今のパソコンも同じなのだが)
・1Byte(バイト)の箱=8bit(ビット)なので、今までお話しした通り0から255までの値を記憶することができる
・MSXの場合、メモリーアドレス(メモリの箱、つまり1Byteのそれぞれの番号)は、0番から65535番まで(十進数表記)=&H0000から&HFFFFまで(十六進数表記)を主記憶装置として記憶することができる
・ちなみに1Byte(バイト)=8bit(ビット)だから、主記憶装置のメモリのスイッチ=1bitの数は65536*8(65536×8)=524288個
「えー、また番号とか数字ばっかりで勘弁してよねーッ!!」
と言われても最初に書いた通り、
・CPUが数字しか分からないので「仕方ないよねーッ!!」
・iTunesのアラニス・モリセットのアルバム「Jagged Little Pill」
・私の好きな曲「You Oughta Know」はトラック2
・You Oughta Knowを聞きたいときは2番を押せば「You Oughta Knowの曲データが読み込まれて聴く(再生する)ことができる」
・ザックリとした説明をすると「音楽CD(CD-DA)の場合はトラック番号がちょうどメモリでいうところのメモリーアドレス」かなー、と(実際はもう少し細かいのだが)
・トラック番号が無いと好きな曲をポンと聴きたくても最初からずっと聴かないといけないので「ちょっと不便」だよねー
・メモリーアドレスは&H0000(0番)から&HFFFF(65535番)までとか番号が多いので一見難しそうだが「CDのトラック番号と意味合いは同じ」
ちなみにアドレスバスというのは配線のことで、
・MSX マシン語入門講座 P33からの引用
・実際にCPUからメモリへ16bit(16本)の配線があるから
もしアドレスバスが8bit(8本)しかなかったら、
・2^8(2の8乗)=256通り、つまりメモリの箱が256個(=256Byte)しかない、もしくはCPUが256Byteまでしか分からないって事になるので「メモリが少なすぎるよねー」
例えば「文字を表示したい」時は多くの場合、
・メモリに記憶されているものを使って文字を表示する
・っつーか、文字以外でも画面表示とかディスクを動かすとか「CPUのお仕事は計算もするけどメモリに記憶してあるものを使ったり記憶を書き換えたりすることも多い」「主記憶装置(メモリ)とはかなり頻繁にやり取りする」
ので、
・「メモリアドレス」や「メモリそのものの」が256Byte(バイト)しかなかったら「1バイト文字だと1バイトのメモリの箱を使う(=1Byte)ので最大256文字、2バイト文字だと1バイトのメモリの箱を2つ使う(=2Byte)ので最大128文字」でいっぱいになる計算だから「文章としては少なすぎるよねー」「俳句だったら31文字だから入るだろうけれど…」
★1bit 1Byte 1kB 1MB 1GB…と容量の話★
そんなわけでMSXはメモリアドレスを16bit(16本)にして、
・最大0から65535番までのByte(バイト)のデータの箱(メモリ)を扱えるようにしている(&H0000から&HFFFFまで)
0番も1つと数えるので、
・Byteの箱の数、つまり容量は最大65536Byte(バイト)ということになり、1バイト文字だったら65536文字入れることができるし、2バイト文字だったら半分の32768文字入れることができる
・これだけ文字が入ったら「何とかなる」よねー?!
ただ、65536Byteってちょっと桁が多すぎるので、だいたい普通は、
・65536Byte=「64kB(キロバイト)」(kは1024倍という意味)と表す
本当はk(キロ)は1000倍(10^3=10の3乗)という意味なので例えば、
・1km(キロメートル)=1000m
・1kg(キログラム)=1000g
ですよね、普通は。
最初にお話ししたようにコンピュータ、特にCPU的には「2進数(2進法)」の世界なので、
・「10^3(10の3乗)=1000」よりも「2^10(2の10乗)=1024」にした方が何かと都合がいいので、便宜上、k=1024倍っていう事にしているだけで…
・さっきの話だと65536という数字は2^16(2の16乗)でピッタリだけれど、10のn乗だと10^4.816(10の4.816乗)くらいになって、しかも少し足りないし…(私は計算があまりできないのでこのあたりで勘弁してね)
・別の言い方で近頃では「KiB(キビバイト)」とか言ったりする
同様に、
・1024kB=1MB(メガバイト)
・1024MB=1GB(ギガバイト)
・1024GB=1TB(テラバイト)…とか
ちなみに、
・1Mb(メガビット)は1MBではない
理由は以前お話ししたように、
・「1Mb=1024kb(キロビット)」ということは1Byte(バイト、省略形は大文字で表す)=8bit(ビット、省略形は小文字で表す)なので、kBに直すと1024kbを8で割った「128kB」となる
(このブログは1ページに30000字しか入らないので次へと続く)
そんなわけでMSXはメモリアドレスを16bit(16本)にして、
・最大0から65535番までのByte(バイト)のデータの箱(メモリ)を扱えるようにしている(&H0000から&HFFFFまで)
0番も1つと数えるので、
・Byteの箱の数、つまり容量は最大65536Byte(バイト)ということになり、1バイト文字だったら65536文字入れることができるし、2バイト文字だったら半分の32768文字入れることができる
・これだけ文字が入ったら「何とかなる」よねー?!
ただ、65536Byteってちょっと桁が多すぎるので、だいたい普通は、
・65536Byte=「64kB(キロバイト)」(kは1024倍という意味)と表す
本当はk(キロ)は1000倍(10^3=10の3乗)という意味なので例えば、
・1km(キロメートル)=1000m
・1kg(キログラム)=1000g
ですよね、普通は。
最初にお話ししたようにコンピュータ、特にCPU的には「2進数(2進法)」の世界なので、
・「10^3(10の3乗)=1000」よりも「2^10(2の10乗)=1024」にした方が何かと都合がいいので、便宜上、k=1024倍っていう事にしているだけで…
・さっきの話だと65536という数字は2^16(2の16乗)でピッタリだけれど、10のn乗だと10^4.816(10の4.816乗)くらいになって、しかも少し足りないし…(私は計算があまりできないのでこのあたりで勘弁してね)
・別の言い方で近頃では「KiB(キビバイト)」とか言ったりする
同様に、
・1024kB=1MB(メガバイト)
・1024MB=1GB(ギガバイト)
・1024GB=1TB(テラバイト)…とか
ちなみに、
・1Mb(メガビット)は1MBではない
理由は以前お話ししたように、
・「1Mb=1024kb(キロビット)」ということは1Byte(バイト、省略形は大文字で表す)=8bit(ビット、省略形は小文字で表す)なので、kBに直すと1024kbを8で割った「128kB」となる
(このブログは1ページに30000字しか入らないので次へと続く)




![[長文] [メモリの仕組み] [その1] 就労継続支援B型事業所(いわゆる作業場/作業所)でメモリの端子の数が違うのはなぜと聞かれたのです 2024年05月09日から06月07まで](https://blogimg.goo.ne.jp/image/upload/f_auto,q_auto,t_image_square_m/v1/user_image/10/4f/109f62834623836694de671fc09569ad.jpg)